The End of Fan-Out Pain: How Context Prefetching and Local Evaluation Cut Tail Latency and Compute at Scale
High‑QPS microservices often suffer from fan‑out request patterns: a single user request triggers dozens to hundreds of downstream calls, amplifying latency and load. This article presents a generic architecture that replaces per‑request fan‑out with context prefetching: fetch stable user context and policy/rule data once (per session or short time window), then perform local eligibility evaluation across many targets (e.g., merchants, items, or partners). In load tests on a large consumer platform, this approach reduced downstream QPS by an order of magnitude, improved tail latency, and lowered compute consumption. This article outlines the design, rollout strategy, and trade‑offs, and positions the approach within the microservices literature. The technique complements widely used microservice styles (API gateway, asynchronous messaging/eventing) and mitigates tail‑latency amplification described in prior work.
Background: Why Fan‑Out Hurts at Scale
Microservices excel at modularity and independent deployment, but distributed coordination introduces latency variability and failure modes. When a request fans out to many services (e.g., an eligibility check for a user across N targets), the end‑to‑end latency is dominated by the slowest sub‑call. As fan‑out width grows, tail latency grows disproportionately, even when most calls are fast—an effect well documented in large‑scale systems.
The microservices literature catalogs these quality‑attribute trade‑offs and typical structures (e.g., gateways, message brokers, database‑per‑service) that teams adopt to balance autonomy with performance and reliability. Surveys and mapping studies show recurring concerns: inter‑service communication overhead, monitoring/observability, and data ownership boundaries.
Literature Review
In the realm of microservices, Dragoni et al. delve into the evolution of this architectural style, identifying challenges related to composition and reliability. Further insights into common architectural patterns such as API gateways, asynchronous messaging, and database-per-service, along with their associated quality trade-offs in industrial contexts, are provided by systematic mappings from Alshuqayran et al. and Taibi et al. Real-world migration practices, including pain points in coordination and observability (especially for replacing fan-out paths), are investigated by Malavolta et al. Finally, Dean & Barroso contribute a theoretical foundation for reducing p99 latency in parallel RPCs, particularly exacerbated by extensive fan-out, and propose designs that aim to reduce variance, informing approaches like prefetch + local evaluation.
Problem Statement
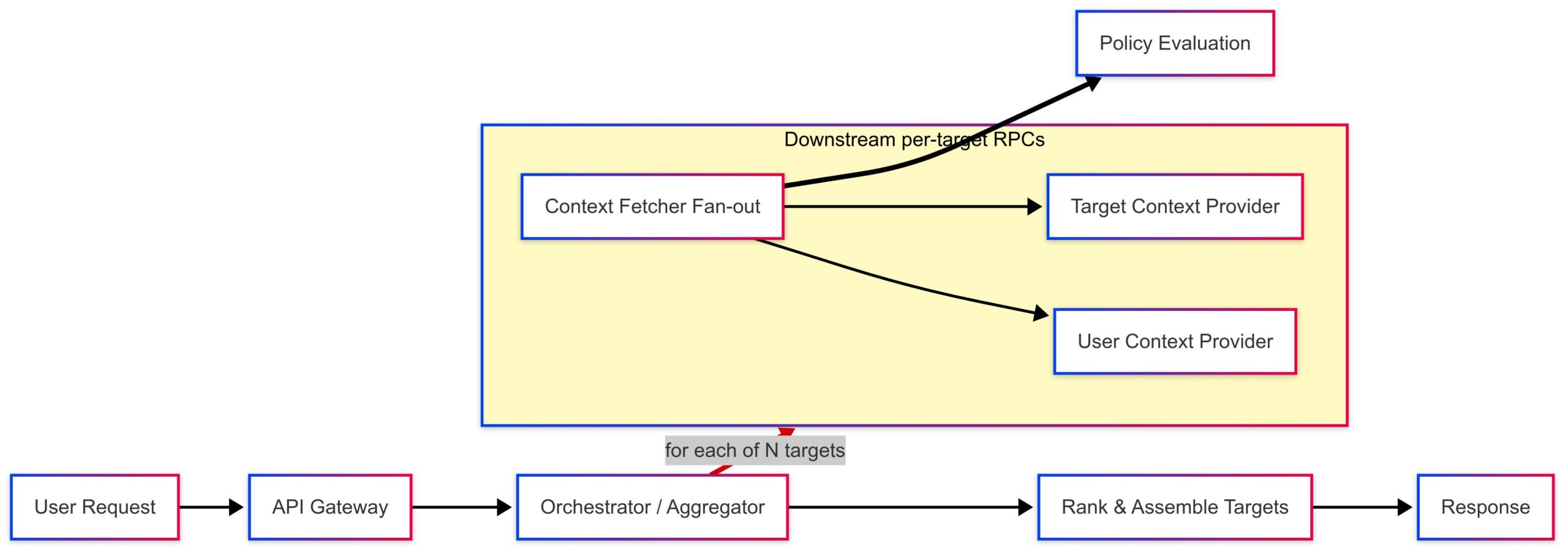
A request arrives to assemble a ranked list of targets (e.g., stores, items, or partners) for a specific user. The system must display which targets confer which benefits (e.g., free delivery, discounts, premium features). A naïve implementation queries a “benefit/policy service” for each (user, target) pair. Under high QPS and wide fan‑out, this balloons into excessive downstream calls, saturating network and CPU, and pushing p99 latency into unacceptable ranges—precisely the “tail at scale” scenario.
Context Prefetching + Local Evaluation
Design goal: Eliminate per‑target user lookups and minimize cross‑service hops.
Key ideas
To ensure a seamless and responsive user experience, particularly under varying network conditions and system loads, we propose a multi-faceted approach to eligibility (user, target) evaluation. This strategy focuses on optimizing data fetching and localized processing.
Prefetch and Cache Stable User Context:
To optimize eligibility checks, proactively retrieve and store stable user attributes, forming a “stable user context.” This foundational dataset should include user memberships (e.g., premium, beta), entitlements, feature flags (e.g., A/B test groups), and cohort attributes (e.g., geographical region, user segment). Prefetching should occur once per user session or with a short Time-To-Live (TTL) to ensure data freshness without excessive re-fetching. This caching significantly reduces latency by minimizing redundant network calls, improving response times for eligibility checks, and lessening the load on backend user attribute management services.
Bulk Fetch and Cache Target-Side Policy/Rule Bundles:
The proposed approach involves consolidating policies and rules into comprehensive bundles. These bundles are subsequently retrieved and applied based on segments, regions, or versions, rather than being fetched individually. This strategy necessitates robust local caching coupled with effective invalidation mechanisms to ensure policy currency. The advantages encompass a reduction in remote calls, expedited policy evaluation, and diminished network overhead, particularly when an orchestrator assesses eligibility for multiple targets.
Evaluate Eligibility Locally with a Shared Library/SDK:
To improve efficiency, eligibility evaluation shifts from remote services to a local component (orchestrator or edge aggregator). This local evaluation uses an SDK with pre-fetched user context and cached policy bundles to check constraints. The SDK, a lightweight and optimized embedded decision engine, eliminates external service calls, reducing latency, enhancing resilience, and enabling faster policy deployment through SDK or policy bundle updates.
This system works by optimizing call graphs, managing latency, and reducing computational overhead. It flattens the call graph from O(N) to O(1) or O(k) per-request calls, minimizing network requests and processing steps. This also reduces tail latency by reducing network hops, leading to more consistent p99 and p99.9 latency. Compute efficiency is improved by running heavy eligibility logic once per request set instead of for each entity, significantly lowering Query Per Second (QPS) for downstream services. These benefits align with distributed systems principles, as highlighted in research like “The Tail at Scale,” by reducing latency amplification and variance.
Architecture Overview
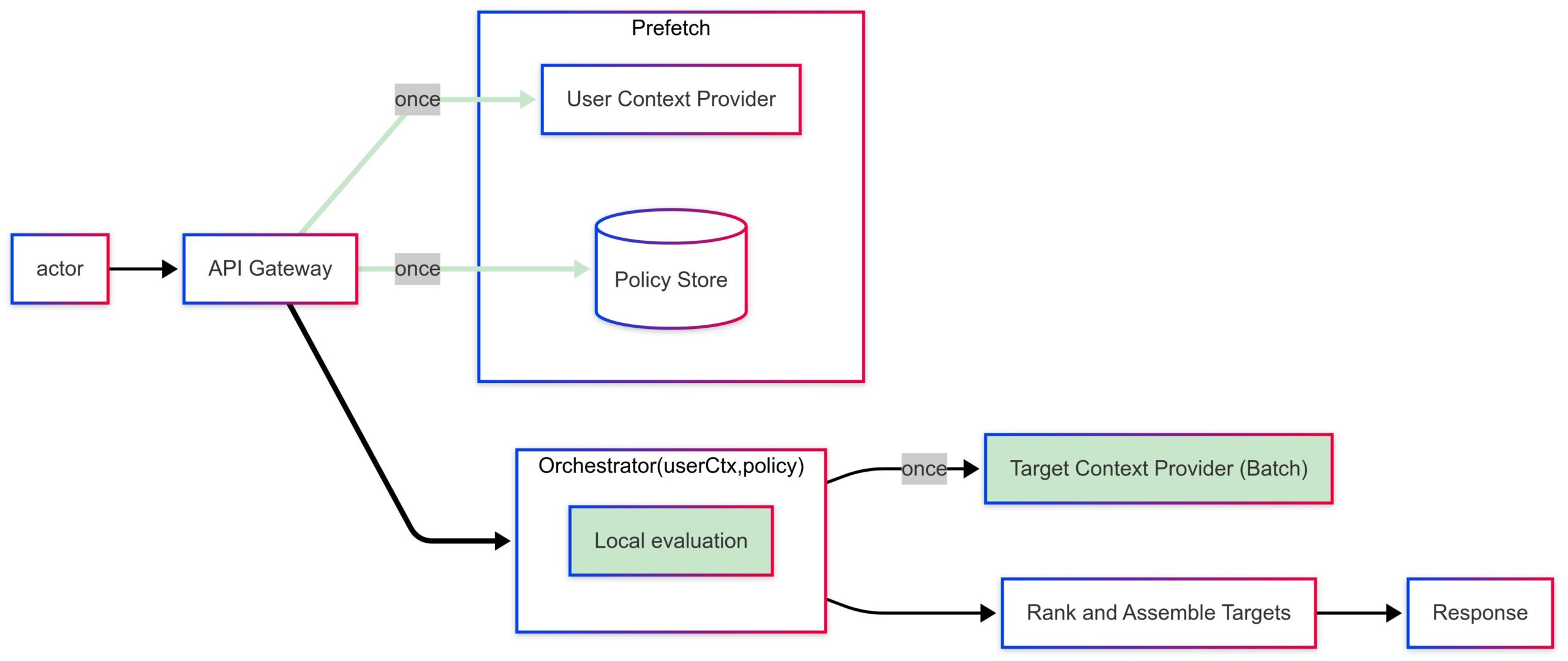
A portable blueprint that fits common microservice styles:
- Ingress/API Gateway receives the user request and forwards it to an orchestrator (can be a BFF or aggregator service). API gateways and BFF patterns are widely reported in microservice pattern surveys.
- Prefetch layer pulls user context from an identity/entitlement service with a session‑scoped TTL.
- Policy cache maintains versioned policy/rule bundles for targets (refreshed via pub/sub or timed pulls). Asynchronous messaging for decoupled updates is a frequent pattern in industrial microservices.
- Local eligibility engine (library/SDK) deterministically evaluates (user_context, policy_bundle, target_attributes) per target.
- Observability captures cache hit rates, evaluation latency, and divergence vs. ground truth to govern TTLs and correctness.
Microservice mapping studies emphasize that such compositions (gateway + async messaging + database‑per‑service) improve maintainability and performance when communication is carefully controlled.
Evaluation
In pre‑production and production canary tests on a high‑traffic consumer workload:
- Downstream QPS dropped by roughly an order of magnitude (fan‑out eliminated; most calls served from prefetch or cache).
- Tail latency (p99) improved materially due to fewer parallel RPCs and reduced variance sources.
- Compute savings accrued both in the orchestrator (batch evaluation) and downstream systems (fewer invocations).
These outcomes are consistent with theory and empirical observations on tail‑latency behavior in wide fan‑outs.
Trade‑offs & Risk Mitigation
- Staleness vs. Freshness: Prefetching introduces TTL decisions; mitigated with short TTLs for sensitive attributes, versioned policy bundles, and event‑driven invalidation.
- Correctness Drift: Guard with parity shadowing, canarying, and automated diff alerts until error rates are near zero.
- Complexity Concentration: The orchestrator becomes smarter; keep the local evaluation library small, deterministic, and well‑tested.
- Observability: Include per‑decision trace tags and cache metrics; mapping studies consistently identify observability as critical in microservices.
Conclusion
Context prefetching converts an N‑way fan‑out into a compact, cache‑friendly evaluation loop. For high‑QPS systems that must annotate many targets per user request, it meaningfully shrinks downstream QPS, improves tail latency, and reduces compute—while aligning with established microservice patterns. As platforms continue to decompose into finer services, strategies that reduce variance and hops will remain central to meeting strict SLOs at scale.
References
- Dean, J., & Barroso, L. A. The Tail at Scale. Communications of the ACM (2013).
- Dragoni, N., et al. Microservices: Yesterday, Today, and Tomorrow. Springer (2017).
- Alshuqayran, N., Ali, N., & Evans, R. A Systematic Mapping Study in Microservice Architecture. IEEE SOCA (2016).
- Taibi, D., Lenarduzzi, V., & Pahl, C. Architectural Patterns for Microservices: A Systematic Mapping Study. CLOSER (2018).
- Malavolta, I., et al. Migrating towards Microservice Architectures: an Industrial Survey. ICSA (2018).



